데이터베이스 수업을 듣기전 JPA로 프로젝트 하고 SQLD 자격증 공부는 수개월 후에 따로 하다보니 관련 개념을 너무 주먹구구식으로 알고 있었다. 정리해보자!
1. 외래키는 왜 쓰는가?
외래키를 생각해보기 전에, 키는 무엇인가? 테이블에서 데이터를 구분할 수 있는
여러 글을 찾아봤는데, 외래키를 사용하는 이유는 두 가지로 대표할 수 있을 것 같다.
1.1. 중복 데이터 관리
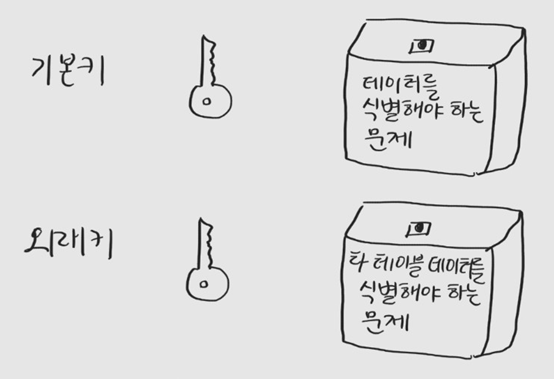
ㅇ기본키와 외래키가 하는 역할
키는 테이블에 있는 레코드들을 식별할 수 있도록 한다.
키만 있다면 유일한 레코드를 뽑아낼 수 있다.
기본키는 데이터를 식별해야 하는 문제를 해결한다.
외래키는 다른 테이블 데이터를 식별해야 하는 문제를 해결한다.
자기 테이블 데이터를 식별해야 하는 이유는 알겠는데, 왜 다른 테이블 데이터를 식별해야 하는가?
다른 테이블에는 그 테이블의 기본키가 있을 것 아닌가?
외래키가 필요한 이유
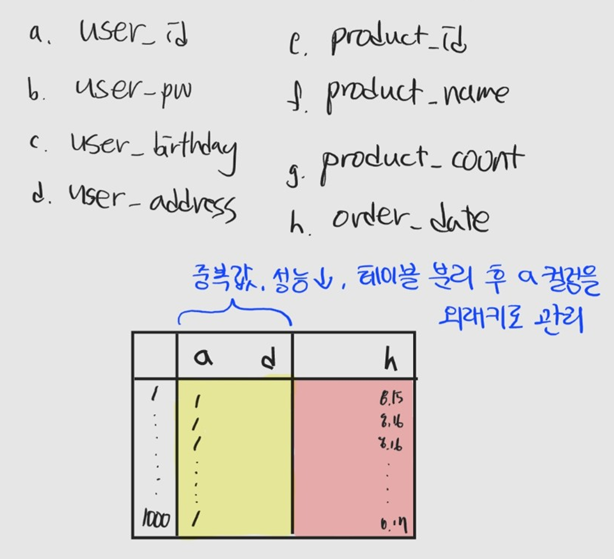
위와 같은 컬림을 가진 테이블을 이용해 사용자가 웹사이트에서 물건을 주문하는 상황을 생각해보자.
이 사이트의 유일한 단골인 한 사용자가 두 달동안 물건을 1000개 샀다. 컬럼 a, b, c, d는 같은 사용자에 대한 정보가 들어갈 것이고 기껏해야 e, f, g, h 컬럼 내용만 달라질 것이다. 같은 정보를 반복해서 저장하는 것은 메모리 낭비다.
이런 경우에는 노란색 영역을 사용자 테이블, 빨간색 영역을 주문 테이블로 나누고 user_id인 컬럼 a를 외래키로 둬야 한다.
1.2. 참조 무결성 원칙
외래키를 사용하는 두번째 이유는 참조 무결성 원칙을 지키기 위해서이다.
참조 무결성 원칙은 기본키가 지정된 테이블과 외래키가 지정된 테이블 사이에서, 외래키로 지정된 컬럼 데이터가 기본키로 지정된 테이블 컬럼값 외 값을 가질 수 없다는 제약 조건이다.
만약 위 예시에서 사이트 단골 사용자가 회원 탈퇴를 한다고 생각해보자.
외래키가 걸려있지 않다면 사용자는 탈퇴했으나 주문 테이블에서 주문자 정보는 남아있을 것이고 수동으로 탈퇴한 회원에 대해 적합한 처리("탈퇴한 회원입니다" 메세지를 띄우는 등)를 하는 데에 관련 유지 비용이 지속적으로 들 것이다.
반면 외래키를 건다면 회원 삭제 연산이 이뤄질 때, 연관된 주문 테이블에서 삭제된 회원이 주문한 정보를 어떻게 처리할 것인지 규칙을 걸어 처리할 수 있다.
외래키는 여러 테이블 간 데이터가 무결하다는 것을 보장해준다.
2. 외래키 없이 Join할 수 있는가?
Join 연산은 나누어진 앞서 살펴본 사용자, 주문 테이블처럼 데이터 중복 방지를 위해 나누어진 두 테이블을 연결해 원하는 데이터를 찾기 위해 필요하다.
Join 연산에는 보통 기본키와 외래키를 사용하도록 언급해서 나는 Join으로 두 테이블을 연결해서 데이터를 뽑아내기 위해 기본키, 외래키를 사용하는 줄 잘못 알고 있었다.
Join 연산에 키는 필수가 아니다. 일반 컬럼으로도 Join할 수 있다.
3. 기존 테이블에 외래키를 도입할 수 있는가?
외래키 없이 Join이 가능하다. 따라서 외래키를 설정하지 않은 데이터베이스도 있을 것이다.
아래 링크를 참고하면 이유는 다양해 보인다.
1. 성능이 느리다.
-> 성능 오버헤드 이슈가 있긴 하지만 현재는 무시할만한 수준이다.
-> 외래키가 속도에 영향을 미치기 때문에 도입하지 않는다는 말에는 모순이 있다. 물론 외래키를 걸고 무결성을 확인하면 추가 연산이 필요하므로 느려지겠지만 외래키를 걸지 않는다고 생각해보자. 프로그램 수준에서 데이터 무결성을 확인하기 위해 사전에 select 연산을 할텐데 이 연산이 외래키를 거는 것보다 빠르다고 할 수 있을까?
-> 단, 성능이 매우아주많이 중요한 증권거래시스템 같은 경우에는 외래키를 도입하지 않을 수도 있다.
2. 기존 데이터가 이미 무결성에 맞지 않아서 외래키를 걸 수 없다.
-> enable novalidate옵션으로 기존 데이터 무결성을 검증하지 않도록 설정하면 된다.
3. 테스트 데이터를 생성할 때 참조 무결성 때문에 불편하다.
-> 개발기간 중에 외래키를 Disable 시키면 된다.
4. 트랜잭션 내에서 부모 테이블과 자식 테이블 관계에 따라 연산 순서가 달라져야 할 수 있다.
-> 외래키를 deferred 옵션으로 만들어 매 문장마다가 아닌, 커밋 시점마다 정합성 검사를 한다.
요약하자면, 속도에 민감한 서비스가 아니라면 데이터 품질을 보장받기 위해 외래키를 사용하는 것이 좋다.
다만 데이터 무결성을 지키려면 개발 과정이 귀찮아지는데 제일 나아 보이는 해결 방법은 외래키를 deferred로 만들고 disable 시킨 후 개발하는 것이다.
자바 기본 타입은 총 8가지로, 메모리 위치에 정수, 실수, 논리 값을 직접 저장한다. 런타임 데이터 영역에서 stack 영역에 생성되고 기본 타입을 사용할 때는 메모리 사용 크기에 주의해 표현할 수 있는 수를 벗어난 값을 저장하지 않도록 한다. 값의 종류는 다음과 같다.
정수 값 (일반적으로 n bit 메모리를 사용한다면 -2^(n-1) ~ (2^(n-1))-1 사이에서 값을 저장할 수 있다.)
byte: 8bit
char: 16bit (유니코드 포함)
short: 16bit
int: 32bit
long: 64bit
실수 값
float: 32bit
double: 64bit
논리 값
boolean: 8bit
2. 참조 타입(Reference Type)
자바 참조 타입은 크게 4가지며, 메모리 위치에 갖고자 하는 값이 저장된 주소를 저장한다. 참조 타입에서 참고하고자 하는 실제 값은 기본 타입과 달리 heap 영역에 생성되므로 참조되지 않는 변수는 garbage collection에 의해 삭제되기도 한다. 참조 타입 값을 비교하기 위해서는 주소를 비교하게 되는 == 연산자가 아닌, equals() 메서드를 사용해야 한다.
배열
enum
문자열
클래스
인터페이스
3. 자바에서 int, Integer는 뭐가 다른가?
int는 기본 타입이고 Integer는 Wrapper class, 즉 참조 타입이다. 사용하려는 용도에 따라 두 타입 중 하나를 선택할 수 있다. parseInt()는 String을 int로 반환하고 valueOf()는 String을 Integer 클래스로 반환한다.
int
Integer
데이터 타입
기본 타입
참조 타입 (Wrapper Class)
특징
산술 연산이 가능하지만, null 초기화 불가
boxing 상태에서는 산술 연산이 불가하지만, null 처리가 용이해 SQL 연동 시 사용한다.
Boxing, unboxing 자료형 변환하기
// boxing: primitive Type -> reference Type
Integer referenceInt = new Integer(primitiveInt);
// unboxing: reference Type -> primitive Type
int primitiveInt = referenceInt.intValue();
// Auto boxing: primitive Type -> reference Type
int primitiveInt1 = 1;
Integer referenceInt = primitiveInt;
// Auto unboxing: reference Type -> primitive Type
int primitiveInt2 = referenceInt;
api를 실행했을 때 예상과 다르게 동작한다면 status code를 확인해 어디서 문제가 발생했는지 파악해야 한다. 단순한 코드를 짤 때는(알고리즘 문제풀이 등) 주요 로직 위아래에 출력문을 찍어 결과를 확인했지만, 실제 프로그램을 개발할 때는 한 api가 동작하기까지 controller, service 등 여러 파일을 거치므로 어디부터 문제가 생긴 것인지 하나씩 출력하며 확인하기 어렵다. System.out.println을 사용하고 지울 때 꼭 필요한 코드를 지우게 될 수도 있다.
디버그 모드 어떻게 쓰는가?
1. 변수가 제대로 넘어왔는지, 원하는 동작이 이뤄졌는지 확인하고자 하는 행 번호를 더블클릭한다.
2. 디버그 모드로 어플리케이션을 실행한다.
3. API를 호출하면 그냥 실행했을때와 달리 브레이크 포인트를 찍어둔 부분을 한 줄씩 거치며 실행 과정을 확인할 수 있다.
4. 변수 상태값을 확인하거나 비정상 종료된 위치를 확인할 수 있다.
5. 코드를 수정하면 자동으로 부트가 재실행되고 새 인자를 넣어 테스트할 수 있다.
디버깅할 때 내가 명심해야 할 점
내 프로그램에는 다양한 오류가 있을 수 있다. 2주 정도 디버깅 늪에 빠져있으면서 느낀 점은 다음과 같다.
1. 문제가 실제로 문제가 맞는지 확인하고 난 후에 수정하자. 의심만으로 코드를 수정했다가 옳은 부분을 잘못되게 수정하고 되돌아온 적이 있다. 이런 고민은 실력을 늘게 해 주지도 않을뿐더러 시간만 낭비하게 한다!
2. 다양한 요인이 프로그램을 오동작하게 할 수 있다. 한번에 모두를 바꾸고 동작을 확인하지 말고 하나씩 확인하자.
Generating equals/hashCode implementation but without a call to superclass, even though this class does not extend java.lang.Object. If this is intentional, add '@EqualsAndHashCode(callSuper=false)' to your type.
프로젝트 import 하고 뜬 경고 문구!
롬복 쓰다가 @Data가 있는 곳마다 @EqualsAndHashCode로 callSuper 옵션 false를 주란다.
@Data는 constructor, getter, setter, toString, equals, hashcode 등 메서드를 자동으로 생성한다.
이때 만들어진 equals와 hashcode 메소드가 부모 클래스 필드까지 고려할지 안 할지를 설정할 수 있다.
- callSuper = true: 부모클래스 필드 값도 동일한지 체크
- callSuper = false: 본인클래스 필드 값만 고려
@Data는 아주 강력해서 코드를 간결하게 짤 수 있다는 장점이 있지만 각 메서드가 만들어졌을 때 코드에 어떤 영향을 주는지 확실하게 알지 못한 채 사용한다면 side effect가 생길 가능성이 다분하다......
이번 기회에 lombok에서 조심해서 써야하는 어노테이션을 몇 가지 알 수 있었는데,
평소에 종종 쓰던 @AllArgsConstructor, @RequiredArgsConstructor는 생성자를 편리하게 만들어준다.
이 어노테이션들은 클래스에 정의된 순서에 따라 생성자 파라미터 순서를 정하므로 특히 자료형이 같은 경우 예상치 않은 동작 결과를 낼 수 있다.
따라서 대안으로 생성자를 하나 만든 뒤 @Builder를 사용하는 것을 추천한다.
빌더 패턴에서는 파라미터 순서로 생성자를 만들었던 @AllArgsConstructor, @RequiredArgsConstructor와 달리, 이름으로 값을 설정하기 때문에 리팩터링 하기 용이하다.
전공 12학점에 월급도 받을 수 있어서 정규학기도, 인턴생활도 하고 싶었던 나에게 꼭 필요한 프로그램이었다.
일반적으로 인턴 전형이 진행되는 기간을 생가하면 약 한달간 최대 세군데 회사에 지원할 수 있다는 점도 큰 장점인 것 같다.
지원 과정은 다음과 같다.
1. 7/5 - 7/14: 희망기업 서류 지원
2. 7/14 - 7/15: 코딩테스트 실시
3. 7/15 - 7/26: 기업별 서류 발표 및 면접 진행
4. 7/27 - 7/28: 인턴기업 확정 처리
(원래는 서류 지원이 13일까지였는데 마지막날 지원자가 모여서 서버가 마비되었는지 서류지원 마감날이랑 코딩테스트 시작 날짜가 14일로 하루씩 밀렸다.)
약 140여개 회사 중 아래 기준으로 지원하고 싶은 회사를 골랐다.
1. 내가 원하는 기술스택을 사용하는 회사인가?
2. 회사에서 만드는 서비스가 흥미롭게 느껴지는가?
3. 대중교통으로 90분 이내에 갈 수 있는가?
나는 수요가 많다는 이유로 스프링 공부를 해왔기 때문에 실무에서 스프링을 사용하는 이유를 직접 겪으며 이해하고 싶었다. 또한 내가 흥미를 가질만한 주제여야 4개월동안 열정을 갖고 즐겁게 참여할 수 있을거라고 생각했다.
그리고 복지(식대, 간식지원)가 많은 회사에 마음이 가버릴까봐 그 부분은 일부러 자세히 읽지 않았다... !
1번, 3번 기준을 만족하는 회사를 리스트업하니 8개 회사가 남았다. 회사가 어떤 서비스를 제공하는지는 회사 홈페이지와 회사 소개 파일에서 찾아봤고 2번 기준으로 3개 회사를 골랐다.
이력서, 자기소개서, 포트폴리오 총 3개 서류를 준비했다.
세 서류 모두 자체 양식을 만들었다. 포트폴리오는 선택사항이긴 하지만 내가 어떤 프로젝트를 했는지 잘 보여줄 수 있을 듯해 따로 만들었다. 셋 다 처음 작성해봐서 요령도 시간도 없었지만 주변 사람들의 도움으로 잘 마무리할 수 있었다. 나는 어떤 구성으로 써야할지 정말 막막했어서 부족하지만 조금이나마 도움이 되길 바라며 글을 남긴다..!
서류를 준비할 때 크게 두가지를 지키려 했다.
1. 쉽게 읽을 수 있는 서류를 만들자. (형식과 내용 모두)
이 서류만 슬쩍 보고도 내가 어떤 사람인지 감이 오게끔, 친절하고 쉽게 작성하는 것을 목표로 삼았다. 어떤 도메인을 가진 사람이든 이해할 수 있을만한 단어를 사용하고 문장구조를 단순하게 만들었다. 줄간격과 줄바꿈, 여백 배치, 폰트를 조절하며 보기 좋은 서류를 만들려고 했다.
2. 채용하는 사람이 궁금할만한 정보를 넣자.
목표는 이렇게 잡았지만 채용담당자가 무엇을 궁금해할지 잘 모르겠더라... 특히 ict 인턴십은 각 회사별로 지원자에게 궁금해하는게 다를 수도 있겠다는 생각이 들었다. 그래서 그냥 구글링으로 이력서 양식과 자기소개서 질문 항목, 포트폴리오 예시를 찾아보며 최대한 일반적인 양식을 만들려고 노력했다. 아래는 내가 작성한 서류 양식이다.
이력서
개인정보(이름, 생년월일, 전화번호, 이메일, 전공 및 전체평점, 주소)
학력 및 경력사항
수상내역 및 출판
보유기술
어학능력
프로젝트 경험 요약
자기소개서
지원동기
내가 지닌 강점
입사 후(혹은 개발자로서의) 포부
포트폴리오
사용할 수 있는 스킬 요약
대표 프로젝트 3개
프로젝트 소개
담당 역할
느낀점
내 성장에 영향을 준 경험 2개(동아리, 연구실)
무엇을 했는가
무엇을 얻었는가
해커랭크에서 코딩 테스트를 봤다.
내가 지원한 회사 중 두 곳은 코딩 테스트를 봤다. 해커랭크에서 12시간동안 5문제를 풀도록 안내받았고 sample test도 있어서 크게 적응이 어렵진 않다. sample case 결과를 보여준다는 점에서 백준보다는 프로그래머스와 유사한 플랫폼이라고 느꼈다. 난이도는 백준 실버4부터 골드5까지 골고루 나오는 것 같다. 코딩테스트 기간이 끝난 후 이틀 내로 결과 리포트가 메일로 왔다. 모범답안도 함께 오니까 참고해서 자신의 코드를 분석해봐도 좋을 것 같다.
운좋게도 세 곳에서 모두 면접을 볼 수 있었다.
면접준비만으로도 이론공부를 빡세게 할 수 있다고 생각해서 붙을 수 있을지 걱정하기보다 그냥 공부하는 마음으로 준비했다. 평소에 기초가 부족했는지 알아야 하는게 많더라..ㅎㅎ 이력서와 자기소개서, 포트폴리오를 보고 예상 질문을 작성하고 자바/스프링 면접 단골질문 리스트를 추가했다. 질문과 답변을 모두 적으니 8장정도 나왔던 것 같다. 세 회사 공통적으로 프로젝트를 진행할 때 갈등상황이 있었는지, 갈등을 어떻게 해결했는지와 이 회사에 지원하게 된 동기를 물었다.
A회사에서는 프로젝트에서 사용한 기술 위주로 왜 그렇게 했는지에 대한 질문을 많이 받았다. 일대일 대면으로 약 40분간 진행했다.
B회사에서는 단순 반복문부터 자바, 스프링, 데이터베이스 등 기술 질문과 팀 프로젝트 관련 질문도 받았다. 일대일 비대면으로 약 30분간 진행했다.
C회사는 내가 한 경험 위주로 질문하셨고 느낀점을 답하면 되어서 가장 편안했다. 일대일 대면으로 약 40분간 진행했다.
A, C 회사에서 면접합격 소식을 들었다.
나는 서류를 넣을 때 1순위, 2순위, 3순위 회사가 없었다. 두가지 이유가 있는데 첫번째 이유는 회사 순위를 매기는 기준에 따라서 순위가 계속 바뀌었고 무엇이 제일 나은 기준인지 헷갈렸기 때문이다. 두번째 이유는 1순위 회사를 정했는데 떨어지면 아쉬움이 더욱 클 것 같아서였다. 선택을 해야만하는 때가 와서 주변에 조언을 구했고 다들 우문에 핵심을 꿰뚫는 답변을 해주셨다. 일이 조금 힘들더라도 네가 가장 성장할 수 있을 것 같은 곳으로 가는 것이 좋다는 것이다. 이 이야기를 듣고 어느 회사를 가는게 좋을지 명료해졌고, 26일에서 27일 넘어가는 자정이 되자마자 바로 A회사 인턴확정 버튼을 눌렀다!
마음은 후련하지만 새로 고민할 거리가 생겼다!
약 1년간 내 단기적인 목표는 인턴을 하는 것 그 자체였다. ict 인턴십에 지원하며 좋은 기회를 얻었고, 이제는 어떻게하면 4개월을 잘 보낼 수 있을지 고민해봐야겠다. 우선은 주기적으로 배운 것과 느낀 점을 쓰려 한다. 매일 한걸음 더 나아가는 사람이 되어야겠다!
깃 정리를 할 때는 자세히 남기지 않았는데 section3에서 JPA를 공부할 때 h2라는 web console을 사용했습니다. 이번 섹션에서는 AWS에서 제공하는 RDS에 대해 알아볼텐데, 그 전에 이 데이터베이스와 RDS의 차이가 뭔지 알아보겠습니다! 데이터베이스는 영구 데이터베이스와 인 메모리 데이터베이스로 나누어 생각할 수 있습니다.
영구 데이터베이스: 실제 메모리에 데이터를 유지하므로 서버가 반송되더라도 다시 사용할 수 있음
인 메모리 데이터베이스: 데이터는 시스템 메모리에 저장되며 프로그램을 닫으면 데이터가 손실됨
H2DB는 자바 기반의 오픈소스 관계형 데이터베이스 관리 시스템입니다. 서버 모드와 임베디드 모드의 인메모리 DB 기능을 지원하고 브라우저 기반의 콘솔모드를 이용할 수 있으며 용량이 가볍습니다. 또한 표준 SQL 대부분 문법이 지원됩니다. 가볍고 빠르며 IntelliJ와의 호환성도 좋기 때문에 어플리케이션 개발 단계의 테스트 DB로써 많이 사용됩니다. 하지만 램에 데이터를 저장하다보니 웹서버를 재부팅하면 기존 데이터가 사라지고 저용량만 지원한다는 한계가 있습니다.
10.2. What is RDS?
만약 직접 데이터베이스를 설치하면 모니터링, 알람, 백업 등을 구성해야 하고 이는 시스템 관리를 복잡하게 만듭니다. Amazon Web Service에서는 클라우드 기반의 Relational Database Service(RDS)라는 데이터베이스 관리 시스템을 제공합니다. RDS를 사용하면 개발자는 데이터베이스 설정, 패치 및 백업과 같은 운영 작업을 자동화해 개발 작업에만 집중할 수 있습니다. 만약 데이터베이스에 갑자기 많은 양의 데이터가 쌓여도 RDS를 사용하면 과금으로 손쉽게 용량을 늘릴 수 있습니다! 그러나 RDS는 과금을 해야 한다는 큰 단점이 있기 때문에 EC2 리눅스 위에 직접 DB를 설치하고 서비스하는 옵션도 생각해볼 수 있겠습니다.