DSC UOS에 2021 Spring Member로 합류했습니다.
ml 공부를 이어서 하자는 다짐에 paper review 팀에서 활동하는데, 용어부터 개념까지 쉬운 게 없네요.
교수님들께서 왜 용어 대부분을 영어로 말씀하시는지 백번 이해했습니다...
무엇을 잘 알아서 글을 쓴다기보다 얕은 지식이나마 잊지 않으려 게시글로 남깁니다.
개념 오류가 있다면 알려주시면 감사하겠습니다.

Real-Time Scene Text Detection with Differentiable Binarization이라는 논문을 리뷰했습니다.
관련 프로젝트를 준비하며 insight를 얻고자 본 논문을 선정했습니다.
text detection분야를 서치하면서 자주 보았던 TextBoxes와 Mask TextSpotter를 제안하셨던 분의 논문이더라고요.

text detection은 이미지에서 글씨가 있는 위치가 어디인지 감지하는 기술입니다. 오른쪽 이미지는 발표자료에서는 영상인데요, text tracking을 하는 모습입니다. detection과는 조금 다른 개념이지만 실시간성이 중요할 때가 있다는 것을 이야기하고자 첨부했습니다.

Segmentation-based method는 픽셀 단위 데이터를 다루므로 text detecting에 많이 쓰이는 기술입니다. 해당 기술은 기울어지거나 회전한 이미지에서도 detection에 강하므로 자주 쓰이는 기술이지만 post-processing이 복잡해 연산량이 많아진다는 단점이 있습니다. accuracy 향상을 위해 progressive scale expansion을 수행한 PSENet, Segmentation 결과에 pixel embedding을 하는 방법으로 픽셀 간 거리를 클러스터링 하는 방법 등이 text detection 분야의 SOTA로 꼽힌다고 논문에서는 언급합니다. 대부분의 기존 방법에서는 segmentation network를 binary image로 만들기 위해 fixed threshold를 사용해서 휴리스틱적 기법으로 픽셀을 그룹화했습니다.

이 논문은 binarization을 위한 threshold를 학습시키는 것을 목표로 둡니다. joint optimalization을 위해 binarization operation을 segmentation network에 삽입하는 것을 목표로 하는데 이렇게 adaptive 하게 optimize 하는 것에는 픽셀을 전경 및 후경과 완전히 구분할 수 있는 장점이 있습니다.

이 목표를 달성하려면 결국 standard binarization function(activate function)을 학습시켜야 하는데, 이 식은 특정 값 이상이면 1, 아니면 0으로 미분 불가능하기 때문에 Differentiable Binarization(DB)이라는 이진화 근사 함수를 사용합니다. 이 논문은 결과적으로 CNN에서 e2e로 binarizationbinarization 할 수 있는 미분 가능한 모듈을 제안했고 semantic segmentation에 대해 빠르게 text를 detectdetect 하는 방법을 제안했다는 점에서 의의를 가지는 것 같아 보입니다.

이 기술은 후술 할 5가지 데이터셋에서 좋은 성능을 보였고 Light-weight backbone이 잘 동작해 탐지 성능이 좋습니다. DB가 horizontal, multi-oriented and curved text에서도 robust한 binarization map을 제공하므로 post-processing을 단순화할 수 있어 속도가 빠릅니다.

related work에서는 text detecting을 위한 regression based, segmentation based method를 소개합니다. Regression-based는 text instance의 bounding box를 regressregress 하는 모델로, 일반적으로 non-maximum suppression과 같은 간단한 post-procession algorithm을 사용합니다. 그러나 휘어있는 글자 모양에도 accurate bounding boxes를 나타내게 하는 한계가 있습니다. Segmentation-based는 bounding box를 얻기 위해 pixel-level prediction과 post-processing을 결합한 방법입니다. detecting 속도를 높이기 위한 방법들은 curved와 같은 irregular shape를 다루지 못합니다. 연구들은 segmentation result를 post-processingpost-processing 해 추론 속도를 줄였으나 이 연구는 training 과정에 binarization을 포함해 정확성과 추론 속도를 높이는 것에 중점을 둔다고 소개합니다.

입력 이미지는 feature-pyramid backbone(FPB)으로 넣습니다. forward forward에서 추출된 의미 정보들을 top-down 과정에서 업샘플링하여 해상도를 올리고 forward forward에서 손실된 지역적인 정보들을 skip connection으로 보충해서 스케일 변화에 강하게(robust) 합니다. 또한 각 layer마다 prediction 과정을 넣어 pyramid feature는 동일한 scale로 up-sampling, cascaded 되어되어 feature F를 생성합니다. feature F를 사용해 P와 T를 생성하고 대략적인 binary map을 계산하고 training시에는 P, T, B가 supervised 되며 text를 detection합니다.

ij는 좌표 지점이고 t는 predefined threshold, T는 adaptive threshold, K는 amplifying factor, B hat은 approximate binary map을 의미합니다. 기존에 사용하던 이진화 함수(standard binarization)는 미분 불가능하기 때문에 training 할 때에 넣어 optimizeoptimize 할 수 없습니다. 개선된 방법에서는 고정된 숫자에서 0과 1을 나누는 것이 아니라, 학습된 값을 기준으로 나뉘도록 differetiable binarization을 적용해줍니다. (SB와 DB를 그린 그래프가 논문에 있는데 두 그래프가 바뀐 게 아닌가 생각이 들어 넣지 않았습니다. 혹시 논문을 읽으신 분이 있다면 댓글 달아주시면 감사하겠습니다...)

(a)는 input image, (b)는 probability map, (c)는 thershold map without supervision, (d)는 threshold map with supervision을 뜻합니다. 논문에서는 text border처럼 생긴 threshold map이 최종 결과에 도움이 된다고 언급하며 border-like supervision을 적용할 것이라고 합니다. 이 모델은 또한 Deformable convolution network를 사용합니다. CNN은 인풋 이미지 종횡비가 획일적이라 extreme aspect 비율을 가진 이미지에 대처하기 어려우므로 뒤에 백본으로 사용될 resnet-18, resnet-50에서 deformable convolution을 사용합니다.
(with supervision without supervision 쪽이 잘 이해가 안 가서 멋진 선배님께 여쭤본 결과, 정보량을 많이 가진 쪽이 더 학습이 용이하고 성능이 잘 나오는 것으로 이해했습니다. 기회가 된다면 깃헙을 뜯어보아야겠어요..)
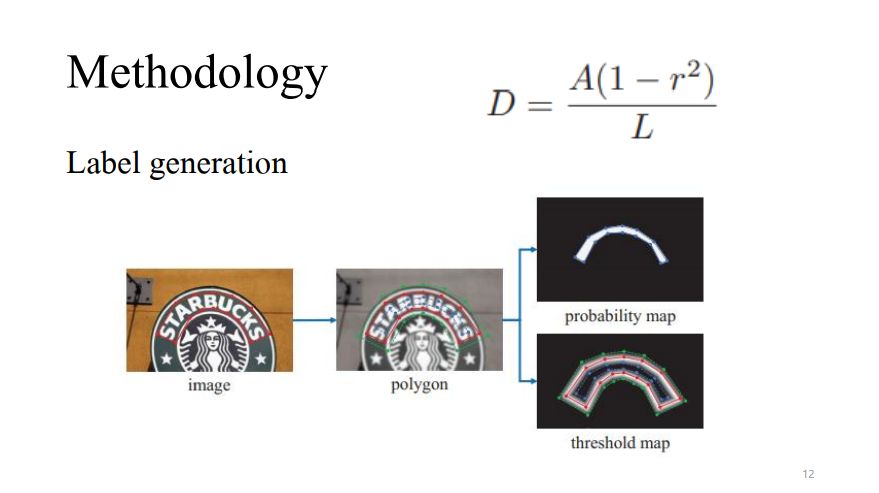
Label을 만드는 과정입니다. (R은 shrink ratio로 0.4)
1. Text image가 주어지면 segment의 set이 나온다.
2. Vertexes가 합쳐져 빨간색 G가 된다.
3. Gs는 폴리곤을 줄여서 파란색, Gd는 늘려서 초록색
4. 이 offset은 Vatti clipping algorithm을 사용한다.
5. Gs와 Gd gap을 텍스트 영역의 테두리로 본다.

각 map의 loss function을 최적화하는 수식입니다. 발표 중 질문을 주셨는데 바로 답변드리지 못해, 멋진 선배님께 여쭤보았습니다. text detection을 위한 모델에서는 해당 픽셀이 글자인지 아닌지에 대한 확률값을 표현해야 하므로 확률 모델링을 용이하게 해주는 binary cross entropy 계열 loss function을 사용한다고 합니다. 만약 확률을 예측하는 것이 아니라 박스 위치를 regression 하는 종류 task에서는 mse, l1, l2등의 loss function을 주로 사용합니다.

학습 과정입니다. 위에 서술한 바와 같이 모든 모델에 대해 SynthText로 1010만 회 반복 훈련합니다. batch 16, learning rate 0.07, power 0.9. weight decay 0.0001, momentum 0.9였고 data augmentation은 random rotation, random cropping, random flipping을 수행했습니다.

Differentiable binarization - Tab 1
-ResNet-18은 3.7%, 4.9% 정도의 성능 향상
-ResNet-50은 3.2%, 4.6% 정도의 성능 향상
Deformable convolution - Tab 1
-ResNet-18은 1.5%, 3.6% 정도의 성능 향상
-ResNet-50은 5.0%, 4.9% 정도의 성능 향상
앞서 언급했던 deformable convolution과 DB 모듈을 각각 사용하거나 사용하지 않았을 때 성능을 두 데이터셋에 대해 비교했습니다. 논문이 나온 후의 랭킹도 궁금해서 papers with code를 봤는데 MSRA-TD500은 2등, CTW1500은 자료는 없지만 5-6등 정도 할 것으로 예상했습니다.

Threshold에 supervision이 있을 때와 없을 때 MLT-2017 dataset에 대해 성능을 비교한 표입니다. Resnet-18은 0.7%, Resnet-50은 2.6 향상했습니다. supervision 여부에 따른 다른 데이터셋에서의 성능도 궁금해졌습니다. “Thr-Sup”는 threshold map에 supervision을 적용한 경우를 뜻합니다.

왼쪽 테이블은 Total-text dataset, 오른쪽 테이블은 CTW1500입니다. DB-ResNet50은 두 데이터셋에서 1.1%, 1.2% 높은 성능을 보였고 속도(FPS)에서도 이점이 있어 보입니다. "MTS"및 "PSE"는 Mask TextSpotter 및 PSENet의 약자입니다.
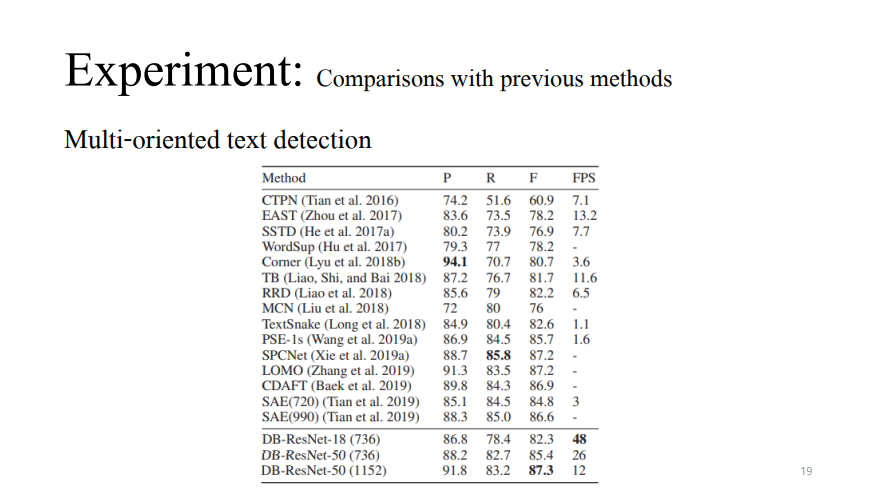
ICDAR 2015는 작고 해상도가 낮은 text instance가 많아서 multi-oriented text detection을 실험한 것이 아닌가 싶었습니다. DB-ResNet-50(1152)는 accuracy에서 sota를 달성했고 이전 sota였던 EAST와 비교해서 DB-ResNet-50(736)이 정확도가 높고 빠르게 실행되는 점을 확인할 수 있습니다.

멋진 선배님께 자문을 구했을 때, text detection은 text recognition과 이어지는 경우가 많습니다. 개발한 모델이 여러 언어에서도 잘 동작하는지 알 필요가 있기 때문에 다국어 데이터셋에 대해 모델을 테스트하는 것에 의의가 있다고 합니다. 해당 논문에서는 대표적인 다국어 데이터셋인 MSRA-TD500과 MLT-2017을 테스트했고 둘 다에서 DB-ResNet-50에서 정확성이 높았습니다.

이 모델의 단점을 꼽자면 텍스트 내부에 있는 텍스트를 detect 할 수 없다는 점입니다. 이 점은 segmentation based scene text detector의 일반적인 한계로 꼽힙니다.

이 논문은 arbitrary-shape를 커버하는 segmentation network에서 동작하는 differentiable binarization process를 제안합니다. 특히 lightweight backbone(ResNet-18)을 사용해도 real-time inference speed를 달성했다고 언급합니다.
'etc' 카테고리의 다른 글
| 2021 하반기 ICT 학점연계 인턴십 지원 후기 (0) | 2021.08.01 |
|---|